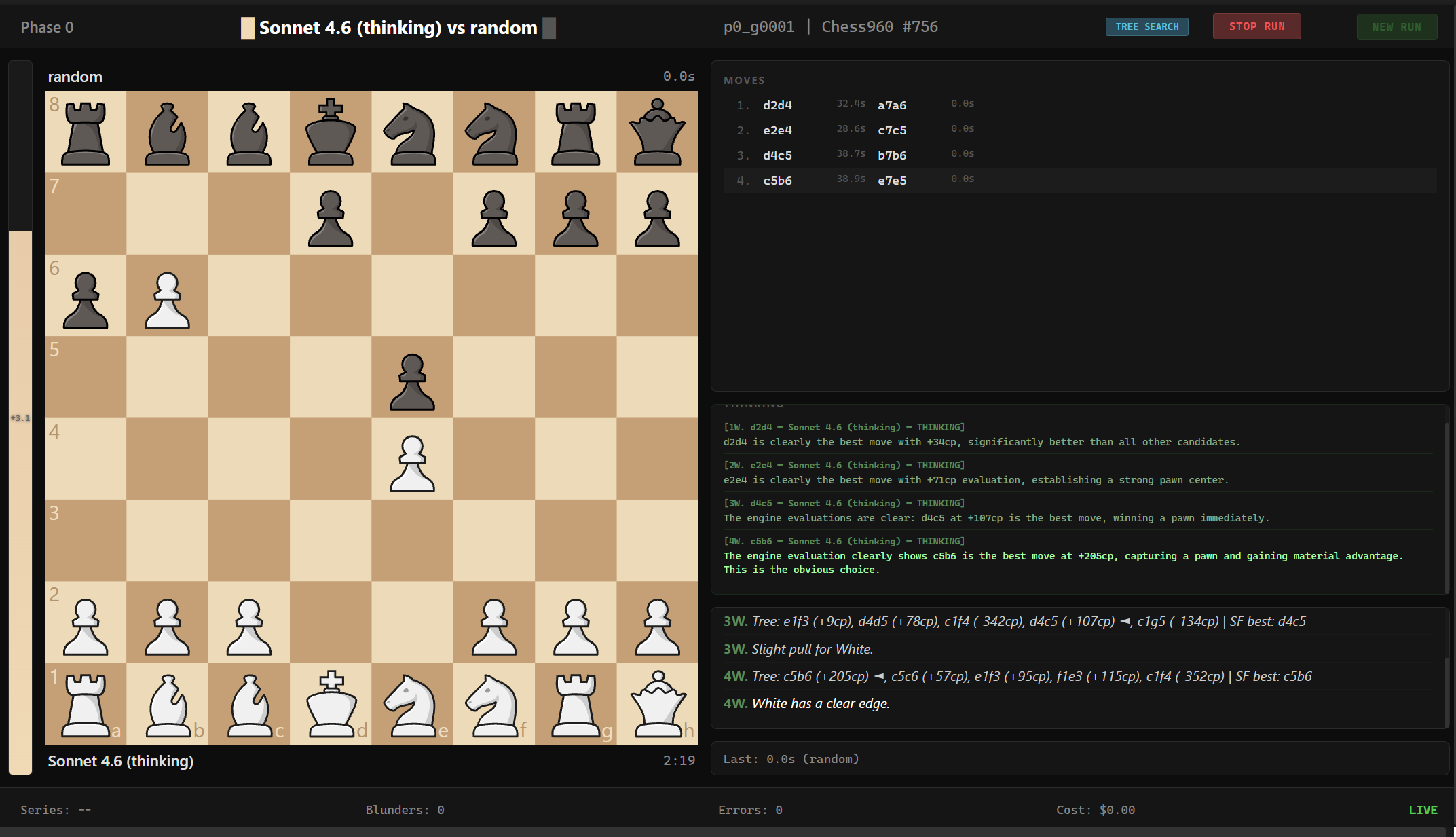
Real-time Stockfish evaluation
Model's actual reasoning
Every move with timing + cost
AI commentary and analysis
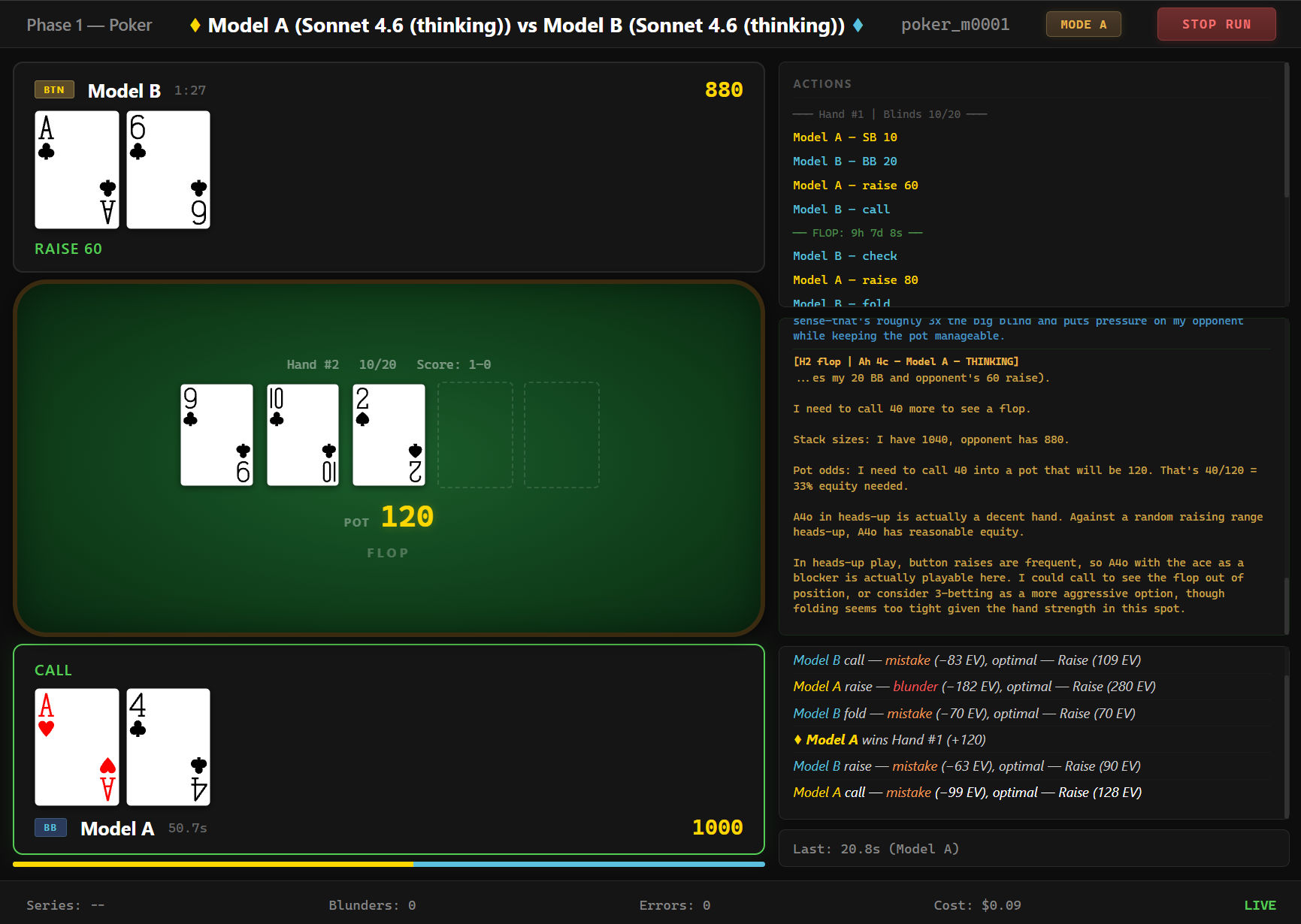
One test that tells you which model is actually smarter.
Strategy, tools, memory, adaptation.
Games are streamed live as they happen. Follow us to get notified.
Every AI benchmark tests naked models in a lab. Fixed questions, known answers, no pressure.
But that's not how anyone uses AI. In the real world, models have tools, memory, and orchestration. They face problems that can't be memorized. They work against opponents who adapt.
The Agzamov Test measures the gap. Strip everything away — how good is the model alone? Now add tools and memory back — how much better does it get? That gap is the Agzamov Score (0–100).
Smart model is not a press release. It's a number.
Four phases. Each one adds more augmentation. The delta tells you what actually helps.
Model vs random opponent. Does the harness even work? Can the model play legal moves?
Naked model vs naked model. No tools, no memory. Just raw capability. This is E0.
Give one model tools + memory, keep the other naked. The score difference = how much augmentation actually helps.
Both models get tools + memory. Does augmentation still help when the opponent has it too?
The Delta
score(with tools) - score(without)
Positive = augmentation helps. Zero = your RAG is useless. Negative = your tools make it worse.
Learning Speed
How many games until augmentation kicks in. Some models figure out their tools in 5 games. Some never do.
Compatibility Matrix
Claude + BrainOps Memory = great. GPT + same memory = meh. Not all models benefit from the same tools.